Proximal Causal Inference: What to Do When Unmeasured Confounding Is Still on the Table
📖 17 min read · Published Apr 18, 2026
Most causal methods begin with a polite fiction: once you adjust for measured covariates, treatment assignment is as good as random. In real clinical data, that is often bullshit. Severity is incompletely captured. Frailty leaks through billing codes. Clinician judgment never fully shows up in the dataset. Proximal causal inference exists for exactly that uncomfortable situation. It asks a harder question: if unmeasured confounding is still there, can proxy variables help us recover the causal effect anyway?
Sometimes, yes. But only if you are explicit about what the proxies are doing and only if you stop pretending every extra variable is automatically helpful. Proximal methods are powerful because they turn hidden confounding into an identification problem involving observed proxies. They are dangerous because people hear “proxies for unmeasured confounding” and immediately start treating messy convenience variables like magic.
The Core Problem
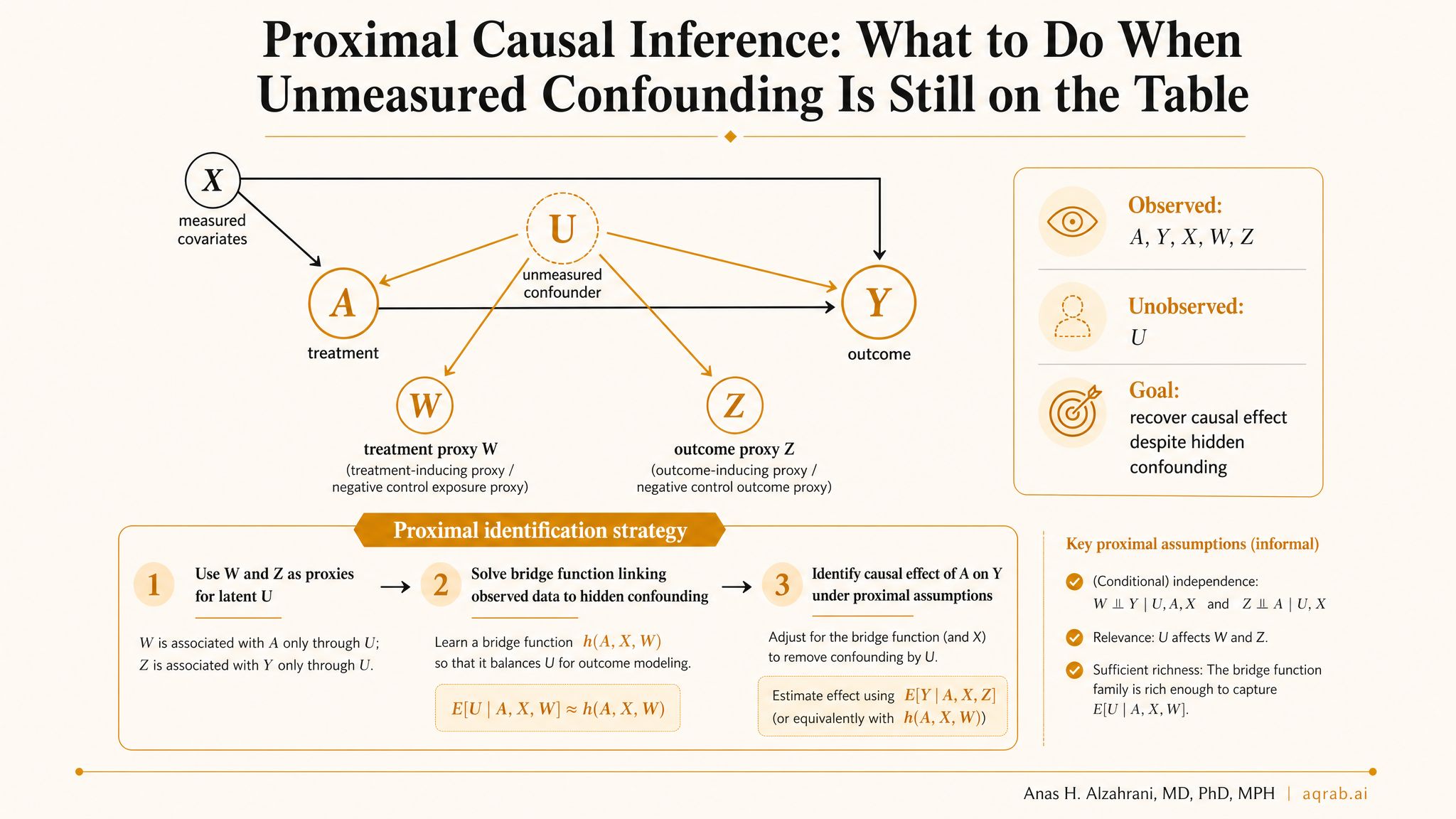
Standard exchangeability says that after conditioning on measured covariates X, there is no residual common cause of treatment A and outcome Y. Proximal causal inference starts from the opposite stance: there is an unmeasured confounder U, and your usual adjustment set is not enough.
Instead of giving up, proximal methods ask whether you observed variables that indirectly carry information about U. If the answer is yes, those proxies may help identify the causal effect even though U itself is missing.
Unmeasured confounder U
The latent disease severity, clinician suspicion, frailty, health literacy, or other factor affecting both treatment and outcome.
Treatment-inducing proxy Z
A variable associated with treatment because it reflects U, but not otherwise directly related to the outcome after conditioning on U, X, and treatment.
Outcome-inducing proxy W
A variable associated with the outcome because it reflects U, but not otherwise directly related to treatment after conditioning on U and X.
The language sounds abstract, but the intuition is simple. If two different observed variables each carry signal about the same hidden confounder, you may be able to reconstruct enough of that hidden structure to identify the causal effect.
Why This Is Not Just “Adjust for More Variables”
This is where people screw it up. Proximal inference is not a permission slip to dump every noisy EHR feature into a model. The method requires variables to play specific causal roles. A treatment-inducing proxy is not just “predictive of treatment.” An outcome-inducing proxy is not just “predictive of outcome.” They must be predictive because they reflect the latent confounder structure.
Clinical intuition:
Suppose you are studying the effect of broad-spectrum antibiotics on mortality in hospitalized patients. True infection severity is imperfectly measured. A clinician’s early escalation decision, certain pre-treatment lab patterns, nursing acuity markers, or utilization signals might act as proxies for that underlying severity. Some proxies may push treatment choice more strongly, while others may reflect expected outcome risk more strongly.
If you cannot defend the proxy role causally, not just statistically, you are not doing proximal causal inference. You are doing hopeful variable stuffing.
The Identification Logic
Proximal methods rely on what are often called bridge functions. These are mathematical objects linking observed proxies to the hidden confounder structure. Instead of observing U directly, you solve an integral equation using W and Z to recover the causal estimand.
In plain English, the method tries to answer this: what function of the observed proxies would behave as if we had controlled for the latent confounder itself?
What makes this interesting:
Standard confounding adjustment fails because U is hidden. Proximal identification works only if your proxies contain enough information about U and satisfy the required exclusion-like conditions. That is a much narrower claim, but when plausible, it is far more honest than pretending no unmeasured confounding exists.
The Two Proxy Types You Actually Need
| Proxy type | What it should capture | Common misuse |
|---|---|---|
| Treatment-inducing proxy Z | Latent drivers of treatment assignment | Using an instrumental variable by accident, or using a post-treatment variable |
| Outcome-inducing proxy W | Latent drivers of prognosis or outcome risk | Using a mediator, downstream complication, or variable affected by treatment |
The separation matters. If Z and W do not supply distinct information about the hidden confounder structure, identification falls apart. If either one is contaminated by direct causal paths you are pretending away, the whole design becomes fragile fast.
A Practical Clinical Example
Imagine an observational study comparing early invasive management versus conservative management for suspected acute coronary syndrome. The true confounder is latent clinical concern, a mixture of symptom nuance, bedside gestalt, subtle ECG interpretation, and physician judgment that is never fully recorded.
Measured covariates X may include age, sex, comorbidities, troponin, and documented vitals. But you still suspect important residual confounding.
- Possible treatment-inducing proxy Z: pre-treatment workflow signals such as rapid cardiology consult, urgency codes, or very early diagnostic sequencing that reflect clinician concern and influence intervention choice.
- Possible outcome-inducing proxy W: rich pre-treatment physiologic or nursing assessment variables that reflect underlying risk but are not themselves part of the treatment decision in the same way.
This is not automatically valid, but it is the right style of thinking. You are not asking whether the variables are predictive. You are asking whether they proxy the hidden disease severity that is confounding your treatment effect estimate.
Main Assumptions, No Hand-Waving
1. Consistency and well-defined treatment
You still need a meaningful intervention contrast. Proximal methods do not rescue vague exposure definitions.
2. Positivity
You still need treatment variation within levels of observed information. No overlap, no credible causal effect.
3. Proxy validity conditions
Z and W must relate to the hidden confounder in the right causal way and not open forbidden direct paths.
4. Completeness
This ugly but crucial condition says the proxies contain enough information about the hidden confounder to identify the bridge functions. Weak proxies kill the method quietly.
That last assumption is the one most people skip because it is mathematically annoying. Unfortunately, it is also where the method lives or dies.
How Proximal Methods Are Estimated
The literature includes several versions, but the big families are easy to summarize.
- Proximal g-computation, which models bridge functions to recover the potential outcome mean.
- Proximal inverse probability weighting, which uses proxy structure to build weights accounting for latent confounding.
- Doubly robust proximal estimators, which combine outcome and treatment bridge components for better robustness.
In practice, this means you are fitting nuisance models and solving bridge equations, often with semiparametric or machine-learning-assisted estimation. So yes, this is more technically demanding than PSM, and that is exactly why casual use is a bad idea.
When Proximal Causal Inference Is Actually Worth Considering
- You have a serious reason to believe unmeasured confounding remains after usual adjustment.
- You do not have a credible instrument.
- You can name plausible treatment-inducing and outcome-inducing proxies before fitting the model.
- Your proxies are measured before treatment and are not obvious mediators or consequences of care.
- You are willing to defend the assumptions in the paper, not hide them in a supplement.
This is especially relevant in EHR studies, pharmacoepidemiology, and registry analyses where latent severity is the real villain and recorded variables only partially capture it.
When It Is the Wrong Tool
- You cannot articulate the hidden confounder you are trying to proxy.
- Your proposed proxies are post-treatment, partially downstream of treatment, or obvious colliders.
- Your design already has cleaner identification through randomization, RD, IV, or target trial emulation.
- You want a fancy method mainly because “residual confounding likely remains” sounds embarrassing in the discussion section.
Hard truth:
Proximal inference is not a credibility upgrade just because it sounds advanced. Bad proxies plus opaque math can make a paper look more sophisticated while being less believable.
Common Mistakes
❌ Treating prediction as proxy validity
A variable can predict treatment or outcome for the wrong reason. Predictive power is not the same thing as causal role.
❌ Using post-treatment information
If your proxy is affected by treatment, you are now mixing confounding adjustment with downstream contamination.
❌ Ignoring completeness and identification fragility
Weak or redundant proxies can make the problem practically unidentified even if the paper says otherwise.
❌ Reporting the estimator without the causal story
If readers cannot understand what Z and W represent clinically, they should not trust the result.
What Reviewers Should Demand
- A clear statement of the target estimand.
- An explicit description of the suspected latent confounder structure.
- A causal defense for each proposed proxy, including why it belongs in the treatment-inducing or outcome-inducing bucket.
- Evidence that proxies were measured before treatment.
- A transparent explanation of estimation strategy, nuisance models, and diagnostics.
- Sensitivity discussion around proxy misspecification and practical identification weakness.
Reviewers should be skeptical in exactly the right direction. Not “this sounds complicated, reject it,” but “show me why these proxies genuinely encode the hidden confounder and why your identification argument is not fiction.”
How It Fits with the Rest of the Causal Toolkit
Proximal causal inference lives in the same family as methods that take design assumptions seriously instead of hiding behind regression. It complements DAG thinking, negative controls, sensitivity analysis, target trial emulation, and high-quality measurement work. In a good workflow, proximal inference is not the first trick you try. It is what you consider after realizing standard exchangeability is too generous and before surrendering the question entirely.
Honestly, that is what makes it valuable. It forces you to stop saying “unmeasured confounding may remain” like a ritual apology and start specifying what remains unmeasured, how it enters treatment and outcome, and whether the data contain indirect traces of it.
Bottom Line
Proximal causal inference is one of the most interesting modern responses to the oldest problem in observational research: hidden confounding that refuses to die. When the proxy structure is plausible, it can move you beyond naive adjustment without requiring a classic instrument.
But this is not a method for people who want causal credibility on the cheap. If you cannot explain the latent confounder, defend the proxies, and show why the assumptions might actually hold, then the fancy estimator is just camouflage. The method is powerful. Your reasoning still has to earn it.