Transportability & External Validity: When Your Causal Estimate Travels, and When It Absolutely Does Not
📖 16 min read · Published Apr 16, 2026
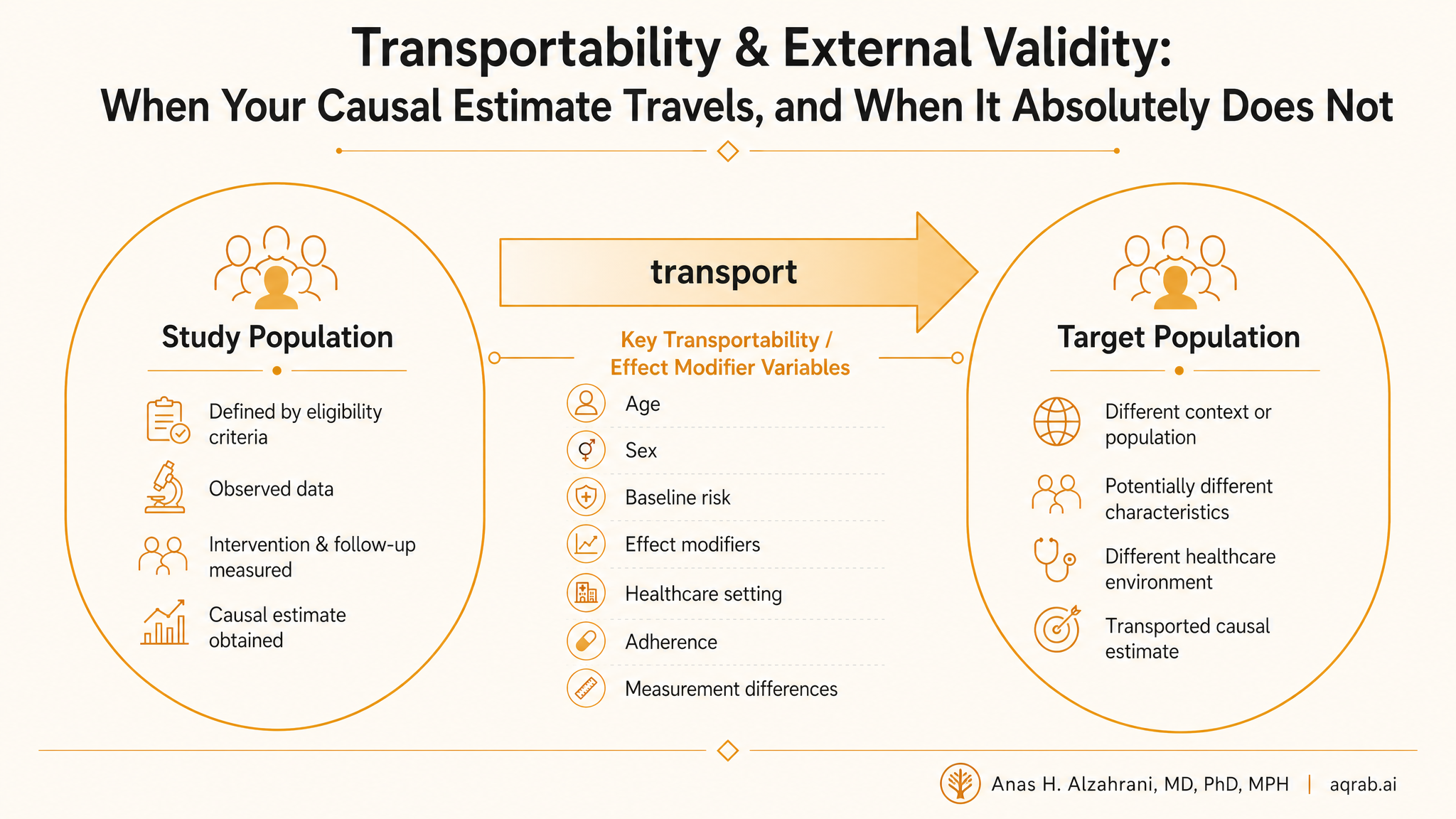
Researchers love saying a result is “generalizable” because the sentence sounds responsible and optimistic. Usually it means almost nothing. A causal effect estimated in one population does not automatically travel to another just because the biology feels similar. If the target population differs in effect modifiers, treatment delivery, outcome measurement, or selection processes, your estimate may stop being relevant the second it leaves the original sample.
External validity is not a vibe. It is a transport problem. You need to define where the estimate came from, where you want it to go, and what assumptions would make that move defensible. If you skip that work, “generalizability” is just confidence wearing a lab coat.
The Core Question
Internal validity asks: is the estimate credible for the people actually studied?
External validity asks: if that estimate is credible here, does it still apply somewhere else?
Generalizability
Extending findings from a study sample to the broader population from which that sample was drawn.
Transportability
Moving findings from one population or setting to a different target population that was not the study source population.
People blur these terms constantly. They should not. Generalizing from a trial sample to eligible clinic patients is already hard. Transporting from a U.S. academic health system to routine practice in another country is a bigger leap with more ways to fail.
Why Effects Fail to Travel
Effect heterogeneity
If treatment works differently by age, baseline risk, comorbidity burden, adherence, or healthcare access, the average effect changes when the population mix changes.
Selection into the study
Trial volunteers and highly curated registry cohorts are often healthier, more adherent, and more monitored than the patients you actually care about.
Different treatment implementation
Same drug name, different dose titration, follow-up intensity, co-interventions, and clinician behavior. That is not the same intervention.
Different outcome measurement
An adjudicated trial endpoint and a noisy claims-based code are not interchangeable outcomes just because both get labeled “mortality” or “hospitalization.”
The ugly truth is simple. If the target population differs on variables that modify the effect, then the transported effect changes. If the study and target settings differ on things that change treatment meaning, then you may not even be transporting the same question.
Clinical example:
A heart failure trial conducted in tertiary centers with frequent follow-up may show a strong benefit because adherence is high and rescue care is immediate. That effect may shrink in routine practice where follow-up is inconsistent and treatment escalation happens late. The drug did not become weaker. The treatment system changed.
The Causal Ingredients You Need
To say an effect travels, you usually need three things:
- A clearly defined source population where the effect was estimated.
- A clearly defined target population where you want to use it.
- A defensible set of measured variables that explain the relevant differences between the two.
In modern causal language, you need to measure the selection variables and effect modifiers that separate study participation from target-population membership. If those are unmeasured, transportability becomes mostly storytelling.
The DAG Logic
DAGs make this cleaner. Imagine a selection node S indicating trial participation or inclusion in the source dataset. If S depends on variables that also modify treatment effect or distort treatment implementation, then the observed effect in the study sample may not equal the effect in the target population.
Conceptual structure:
- X influences both study selection S and outcome Y.
- X may also modify the treatment effect of A on Y.
- If the distribution of X differs between source and target, the average causal effect can differ too.
This is why the right question is not “was the trial multicenter?” The right question is “did the study observe the variables that matter for transporting the effect?” Multicenter branding does not rescue missing structure.
How People Actually Do This
In practice, transportability often relies on reweighting or standardization. You model study participation or target-population membership using measured covariates, then reweight the source sample so it resembles the target.
Main tools:
- Inverse-odds-of-sampling weights
- Standardization / g-computation to the target covariate distribution
- Calibration weighting and other trial-to-target-population methods
Mechanically, this is not exotic. Conceptually, it is demanding. The weights only work if you measured the right transport variables, specified the model reasonably well, and still have overlap between source and target populations.
Overlap Matters More Than Enthusiasm
If the target population contains many patients who barely resemble anyone in the source study, the transported estimate becomes unstable or meaningless. No amount of weighting rescues a target that lives outside the support of the source data.
Hard truth:
If your source data barely contain older frail patients, patients with severe multimorbidity, or patients from low-resource settings, then you do not “know enough” to transport effects there. You have a gap, not a generalization.
A Trial-to-Target Example
Suppose an RCT of intensive blood pressure control enrolled highly selected participants with excellent medication adherence and frequent lab monitoring. You want to apply the result to a broader hospital network population.
Start by asking whether key effect modifiers and transport variables are available in both datasets, for example age, chronic kidney disease, diabetes burden, frailty proxies, baseline blood pressure, and healthcare access. Then ask whether the intervention is really the same. If “intensive control” in the trial meant monthly visits and aggressive titration, but in routine care it means a note in the chart and wishful thinking, you are already drifting off question.
Reweighting the trial sample toward the hospital-network covariate distribution may help, but only after you are honest about treatment delivery and overlap. Otherwise you are transporting an idealized protocol into a different world and pretending the estimate is portable.
Common Mistakes
❌ Confusing representativeness with transportability
A representative sample is helpful, but causal transport still depends on measured effect modifiers and comparable treatment meaning.
❌ Treating p-values the same across populations
A significant effect in the source does not imply a similar effect size in the target. Statistical significance is not a passport.
❌ Ignoring treatment delivery differences
You cannot transport a tightly controlled trial protocol to chaotic routine care without checking whether the intervention still exists in recognizable form.
❌ Hiding overlap failure
Extreme transport weights are not a minor technical issue. They are evidence that your target is asking the source data to answer a question it cannot support.
What Reviewers Should Ask
- What exactly is the target population?
- Why should the source effect equal the target effect after conditioning on the measured variables?
- Were the transport variables measured in both source and target datasets?
- Was overlap checked and reported?
- Does the intervention mean the same thing in both settings?
- Were sensitivity analyses done around transport assumptions?
If the paper never defines the target population precisely, the external-validity claim is already mush. If it never discusses effect modification or overlap, it is usually worse than mush. It is marketing.
What to Say Instead of “Generalizable”
Most papers should retire that lazy adjective and say something specific instead:
- “The estimate is internally valid for the enrolled population.”
- “Transport to routine care may be limited by lower adherence and different baseline risk.”
- “We reweighted the trial to a target registry population using prespecified covariates.”
- “External validity remains uncertain because key effect modifiers were unavailable.”
That language is less sexy and far more honest.
Bottom Line
External validity is not a free bonus that appears after internal validity. It is a second causal problem with its own assumptions, data requirements, and failure modes. If you want an estimate to travel, prove that the road exists.
If not, say the uncomfortable thing plainly: the study may be credible for the people observed, but we do not yet know whether that effect survives contact with the population we actually care about. That is not weakness. That is methodological adulthood.