Active Comparator New-User Design: The Observational Study Upgrade Most Drug Papers Need
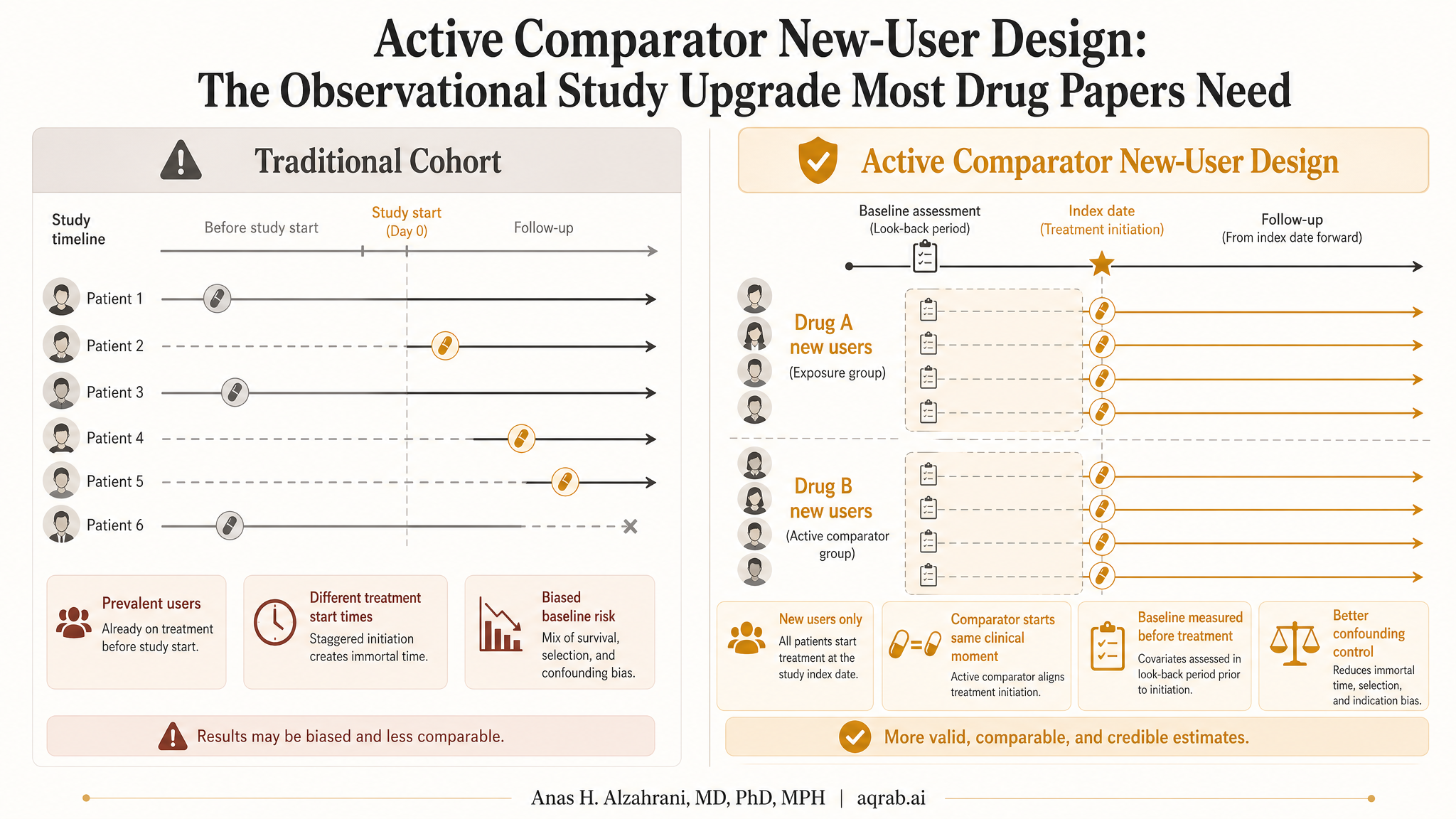
A huge share of bad drug-effect papers make the same mistake: they compare people who start a treatment to people who are not doing anything comparable, then act surprised when the treated group looks sicker, riskier, or more closely monitored. That is not a subtle modeling issue. That is a design failure. The active comparator new-user design is one of the cleanest ways to fix it.
The idea is brutally practical. Compare patients when they initiate treatment, not after they have already survived on it for months or years, and compare them to patients starting a clinically plausible alternative, not to an irrelevant “non-user” bucket. This does not eliminate bias completely, but it usually gives you a study that deserves to exist.
The Core Idea
The design has two parts, and both matter.
- New-user: include patients at treatment initiation so time zero is aligned and baseline covariates are measured before exposure starts.
- Active comparator: compare one treatment to another realistic treatment option used for the same indication.
Together, these choices reduce three disasters at once: confounding by indication, prevalent-user bias, and immortal time bias. That is why this design is a workhorse in serious pharmacoepidemiology.
Why “Treated vs Untreated” Is Usually Garbage
If you compare people who start a statin to people who never start any lipid-lowering treatment, you are not comparing exchangeable groups. You are comparing different clinical decisions, different risk profiles, and often different relationships to the healthcare system. One group had a reason to start. The other group had a reason not to, or had no opportunity, or had less contact, or had lower measured risk. Regression does not magically erase that mismatch.
Hard truth:
“No treatment” is often not a comparator. It is a selection mechanism pretending to be a control group.
An active comparator is better because it keeps the clinical question honest. If both groups were candidates for treatment and both were actually started on something, the reasons driving treatment choice are usually narrower and more measurable.
Why Prevalent Users Corrupt the Study
Including patients who are already on treatment sounds efficient, but it quietly selects survivors. To be a prevalent user, a patient had to start treatment in the past, tolerate it, remain adherent enough to still be observed, and avoid early events that might have stopped therapy or removed them from follow-up. That means you are conditioning on post-baseline history before your study even starts.
New-user designs avoid that mess by entering patients at initiation. Baseline really means baseline. Early harms, early discontinuation, and early benefit are all allowed to exist instead of being filtered out by design.
What Problem This Design Actually Solves
Confounding by indication
Patients receiving different drugs for the same condition are usually more comparable than treated versus untreated patients.
Prevalent-user bias
Restricting to initiators prevents survivor selection and lets you measure real baseline covariates.
Immortal time bias
Time zero is defined at treatment start, so nobody has to survive a hidden waiting period to qualify.
Interpretability
The causal question becomes clinically meaningful: what happens if we start drug A instead of drug B?
A Clinical Example
Suppose you want to estimate whether initiating an SGLT2 inhibitor reduces heart-failure admission compared with initiating a DPP-4 inhibitor in adults with type 2 diabetes. That is a solid active comparator question. Both are real treatment options, both arise in diabetes care, and both are started by patients entering a treatment decision point.
Now compare that with SGLT2 initiators versus all patients with diabetes who are not on an SGLT2. That second design is a dumpster fire. It mixes untreated patients, patients on older regimens, patients with contraindications, patients with different disease stages, and patients who never reached treatment intensification. The estimated effect is immediately harder to interpret and far easier to bias.
The Comparator Is Doing More Work Than Most Authors Realize
Picking the comparator is not clerical. It is one of the main identification moves in the whole study. The best comparator usually shares:
- the same underlying indication,
- a similar treatment-decision moment,
- similar healthcare contact intensity, and
- a plausible role in the same therapeutic line.
If the comparator comes from a different point in the care pathway, you can reintroduce bias even while congratulating yourself for using an active comparator. Drug A versus rescue therapy, or first-line drug versus last-line drug, is often just severity confounding in a nicer suit.
Design Checklist Before You Touch the Model
- Define the clinical decision point.
- Identify true treatment initiators only.
- Choose an active comparator used for the same indication and line of care.
- Measure baseline covariates before initiation, not after.
- Specify follow-up from a shared time zero.
- Decide whether the estimand is intention-to-treat-like, as-treated, or per-protocol.
- Check overlap before getting seduced by the outcome model.
What the DAG Logic Looks Like
In DAG terms, the design is trying to shrink the ugliness of the backdoor path between treatment and outcome by conditioning the comparison on a more homogeneous treatment decision. You do not eliminate all unmeasured confounding, but you often move from “wildly incomparable” to “plausibly comparable after adjustment.” That is a major gain.
The active comparator also improves positivity. If both treatments are realistic choices for similar patients, overlap is usually better than in treated-versus-untreated designs where some patients had essentially zero probability of treatment initiation in the first place.
Where Analysts Still Screw This Up
Using a fake active comparator
If the comparator reflects a different severity tier, contraindication profile, or treatment line, the design is still confounded by clinical decision structure.
Failing to enforce a washout period
Without a clean look-back window, “new users” can secretly be restarters or intermittent users.
Adjusting for post-initiation variables
Covariates measured after treatment starts can become mediators or treatment-induced colliders.
Ignoring treatment switching and discontinuation
The design question and analysis estimand must match. Otherwise the paper becomes a pile of mixed interpretations.
How This Pairs With Other Causal Tools
The active comparator new-user design is not a replacement for causal analysis. It is the foundation that makes later analysis less stupid. After the design is set, you can still use propensity scores, inverse-probability weighting, targeted learning, negative controls, or outcome regression. But those tools work better when the cohort itself was built around a credible comparison.
This is the point many papers miss. Advanced adjustment cannot rescue a comparison that never made clinical sense. Design first, estimator second.
What Reviewers Should Ask
- Why is this comparator clinically appropriate at the same decision point?
- How was new use defined, and what washout window was used?
- Were baseline covariates measured before treatment initiation?
- Does follow-up begin at a shared time zero for both groups?
- What treatment changes, discontinuation, or switching occurred after initiation?
- Is the estimand aligned with the follow-up and censoring strategy?
- Do the exposure groups actually overlap on measured baseline risk?
If a paper cannot answer those cleanly, it should stop flexing its hazard ratio and go fix the cohort.
The Practical Bottom Line
The active comparator new-user design is not glamorous, which is exactly why it matters. It forces the study to mirror a real treatment decision between plausible alternatives and to start follow-up when that decision is made. That alone knocks out an absurd amount of avoidable bias.
If you are doing observational comparative effectiveness research and your design is still treated versus untreated or new users mixed with long-term survivors, you do not have a modeling problem. You have a credibility problem. Start by fixing the comparison.
Keep reading
Don't stop at one method.
Good methods judgment comes from contrast. Read the neighboring guides, see where the assumptions diverge, and avoid treating every observational problem like it needs the same hammer.
Prevalent-User Bias: When Your Drug Study Starts After the Interesting Harm Already Happened
A practical guide to prevalent-user bias for clinical researchers. Covers depletion of susceptibles, survivor selection, post-treatment baseline covariates, and what reviewers should demand before trusting late-entry treatment cohorts.
Washout Periods: When “New Use” Is Just Old Use with Better PR
A practical guide to washout periods for clinical researchers. Covers new-user definitions, refill cycles, intermittent treatment, data-history limits, and what reviewers should demand before trusting an incident-user cohort.
Exposure Lagging: When Your Induction Window Becomes Wishful Thinking
A practical guide to exposure lagging for clinical researchers. Covers induction periods, reverse causation, protopathic bias, estimand drift, and what reviewers should demand before trusting a lagged analysis.