Selection Bias: When Your Study Sample Is the Problem
Selection bias is the kind of problem that ruins a study before the model even gets a chance to embarrass itself. If the people who enter your analysis are systematically different from the people who should have been eligible for the question, your estimate is already leaning crooked.
My take is simple: most researchers obsess over confounding and barely think about who made it into the dataset, who got excluded, who dropped out, and who had complete data. That is backwards. A beautifully adjusted model built on a biased sample is still a biased study.
What Selection Bias Actually Is
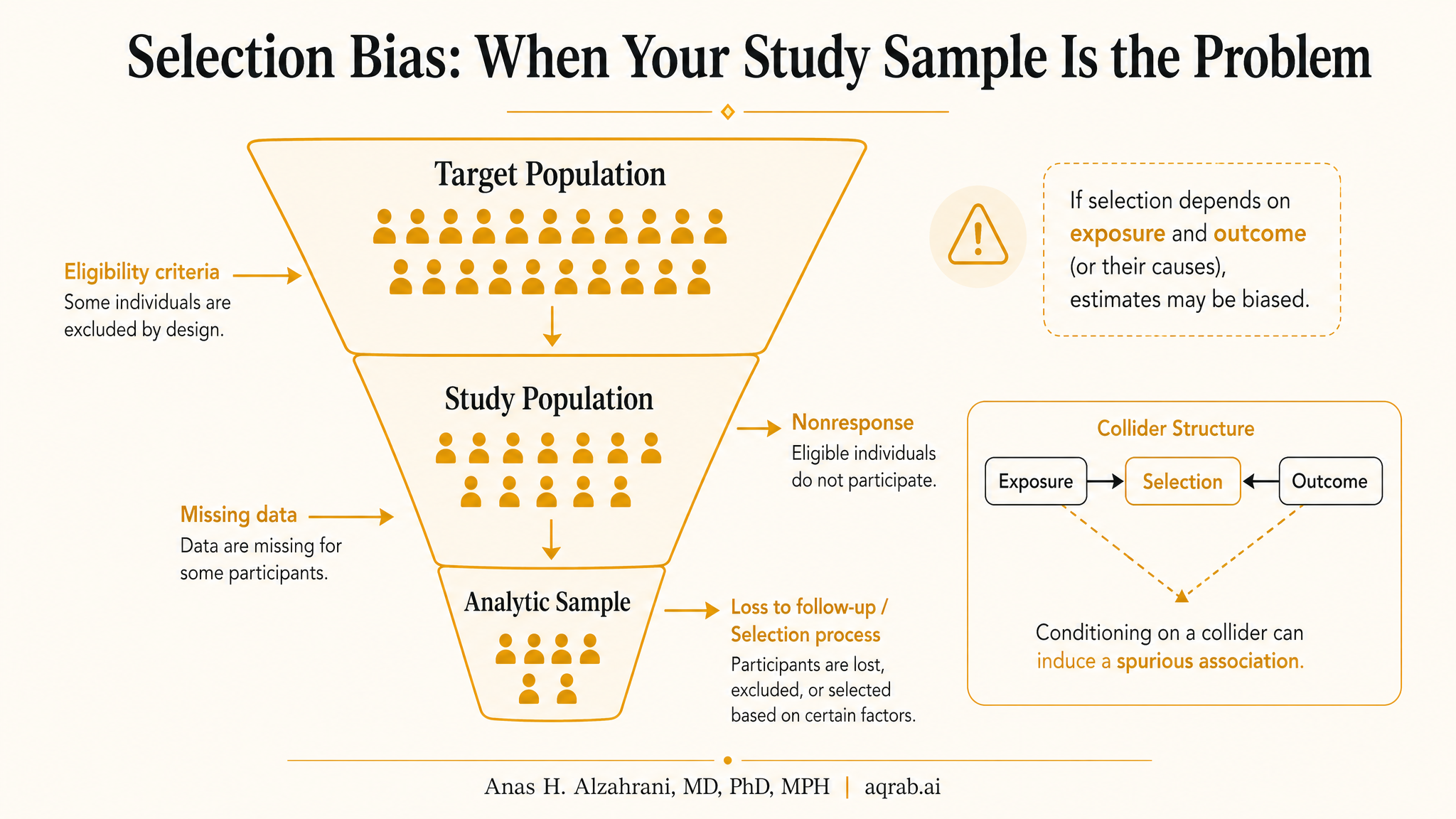
Selection bias happens when inclusion into the analytic sample depends on factors related to exposure, outcome, or both. In plain English, the people you end up analyzing are not just a smaller version of the target population. They are a distorted slice created by referral, survival, eligibility rules, loss to follow-up, missing data, or measurement processes.
Core problem:
If entry into the analysis is affected by variables tied to treatment and outcome, the observed association can be manufactured by the selection process itself.
This is why selection bias often overlaps with collider bias. Conditioning on participation, survival, complete records, or clinic attendance can open a noncausal path that was not there in the source population.
The Fast Clinical Example
Imagine a study comparing two cancer treatments using data from a tertiary referral center. Patients receiving Treatment A look like they survive longer. Tempting result, but who made it to that center?
- Healthier patients may have been referred because they were fit enough for advanced therapy.
- Patients with aggressive disease may have died before referral or before treatment eligibility workup.
- Socioeconomic factors, geography, and insurance can shape who enters the analytic cohort.
If entry depends on prognosis and treatment opportunity, the comparison is already contaminated. The sample is telling you about referral pathways, not just treatment effect.
Where Selection Bias Hides in Real Studies
At cohort entry
Referral patterns, survivorship to enrollment, eligibility screening, and clinic attendance determine who gets counted.
During follow-up
Loss to follow-up, informative censoring, treatment discontinuation, and differential measurement can bend the estimate over time.
At analysis
Complete-case restriction, excluding patients with missing covariates, or conditioning on post-baseline events can create a fake analytic population.
At publication
Studies sometimes quietly present a convenient subset and talk as if it represents everyone who mattered.
Common Forms You Should Recognize Immediately
Referral bias
Specialty centers do not receive a random sample of patients. They receive filtered patients shaped by access, severity, clinician preference, and geography.
Survivor bias
If patients must survive long enough to be observed, enrolled, or classified, early deaths vanish and the remaining sample looks falsely favorable.
Loss-to-follow-up bias
When dropout depends on prognosis, side effects, or treatment response, the patients you still observe are no longer comparable to the ones you lost.
Complete-case bias
Deleting patients with missing data is not neutral. Missingness often tracks illness severity, chaotic care, socioeconomic disadvantage, or system failure.
Why Adjustment Does Not Automatically Rescue It
Researchers love to say they adjusted for baseline differences, as if selection happens only through measured covariates. That is fantasy. If the process determining who enters the analysis is itself informative and partly unmeasured, regression is operating downstream of the damage.
| Problem | Why it matters | What helps |
|---|---|---|
| Referral filtering | Your cohort differs from the target population before analysis begins | Clear target population definition, multisite sampling, transportability thinking |
| Informative dropout | Observed outcomes come from a nonrandom subset over time | Inverse probability of censoring weights, careful retention strategy, sensitivity analysis |
| Complete-case restriction | Missingness creates a selected analytic sample | Multiple imputation when defensible, missingness diagnostics, transparent exclusions |
| Conditioning on a collider | Selection itself can induce a false association | DAG-based design, do not restrict on post-exposure or shared-effect variables without justification |
Selection Bias vs Confounding
Confounding is about causes of both treatment and outcome that exist before you estimate the effect. Selection bias is about who gets into the analysis or remains observable. They often travel together, but they are not the same failure.
If you do not separate those questions, you end up throwing confounder adjustment at a selection problem and calling it sophistication.
The Complete-Case Trap
Here is a mistake I see constantly: authors start with 12,000 patients, drop 4,800 because of missing laboratory values or incomplete follow-up, run the analysis on the remainder, then bury the exclusions in a supplement. That is not housekeeping. That is a new cohort.
- Missing data may be more common in sicker patients.
- Follow-up gaps may be worse among patients with lower access or poorer adherence.
- Lab measurement may be driven by clinical suspicion, which already predicts the outcome.
Once you restrict to complete cases, you may be conditioning on health system engagement, survivorship, or clinician concern. The analysis becomes clean-looking and causally dirty.
Loss to Follow-Up Is Not Just a Nuisance
In longitudinal research, dropout is often informative. Patients disappear because they are getting worse, because they improved and stopped coming, because treatment side effects drove them away, or because structural barriers disrupted care. Any of those can differ by treatment group.
If the probability of remaining under observation is related to future outcomes, your observed outcome data are selected. This is why inverse probability of censoring weights matter. They are not academic decoration. They are an attempt to reconstruct the cohort you started with before follow-up selectively hollowed it out.
How DAGs Help
A good DAG makes selection bias easier to see because it forces you to draw the variable that determines inclusion. Once you add a node for study participation, complete records, survival to enrollment, or observed follow-up, you can ask the right question: what arrows point into that node?
If both treatment and outcome causes feed into selection, conditioning on selection can open a noncausal path. That is the logic. Without the graph, people routinely condition on participation as if it were harmless.
What Good Studies Do Instead
Design the target population explicitly
Define who the inference is for before touching the data. Then judge whether the observed sample actually represents that target.
Report exclusions honestly
Show how many patients were lost at each step and why. If half the sample vanished, that is a headline, not a footnote.
Model censoring and missingness when appropriate
Use inverse probability weighting, imputation, or sensitivity analyses when the selection process is likely informative.
Stress-test external validity
Ask whether the estimate applies outside the selected sample. If not, say so directly instead of pretending the study is universal.
Reviewer Red Flags
- No flow diagram or unclear exclusion steps.
- Massive complete-case losses with no comparison of retained versus excluded patients.
- Dropout rates that differ by treatment group without censoring diagnostics.
- Single-center or specialty-center cohorts making broad population claims.
- Language like “after excluding patients with missing data” with zero discussion of what caused the missingness.
When you see those, do not let the polished regression table hypnotize you. The causal problem may be upstream of the model.
The Bottom Line
Selection bias is not a minor technical annoyance. It is one of the main ways observational studies become persuasive fiction. If the path into your sample is shaped by prognosis, treatment, measurement, or follow-up, your analysis can be wrong even when the code is flawless.
The discipline here is simple but rare: define the target population, map the selection process, treat exclusions as causal events, and stop pretending that a final regression model can wash away every design failure. If your sample is broken, your estimate is living on borrowed credibility.
Keep reading
Don't stop at one method.
Good methods judgment comes from contrast. Read the neighboring guides, see where the assumptions diverge, and avoid treating every observational problem like it needs the same hammer.
Bias Amplification: When Adjustment Makes Unmeasured Confounding Worse
A practical guide to bias amplification for clinical researchers. Covers near-instruments, noisy severity proxies, treatment-prediction traps, and why the wrong adjustment variable can magnify residual confounding instead of reducing it.
Confounding by Indication: When Sicker Patients Make Treatments Look Dangerous
A practical guide to confounding by indication for clinical researchers. Covers treatment selection, severity-driven prescribing, contraindication bias, why routine adjustment often fails, and how to design observational comparisons that do not confuse prognosis with treatment effect.
Proximal Causal Inference: What to Do When Unmeasured Confounding Is Still on the Table
A practical guide to proximal causal inference for clinical researchers. Covers proxy variables, treatment-inducing versus outcome-inducing proxies, bridge functions, completeness, and why this method is powerful but brutally assumption-heavy.