Causal Forests: Finding Treatment Effect Heterogeneity Without Fooling Yourself
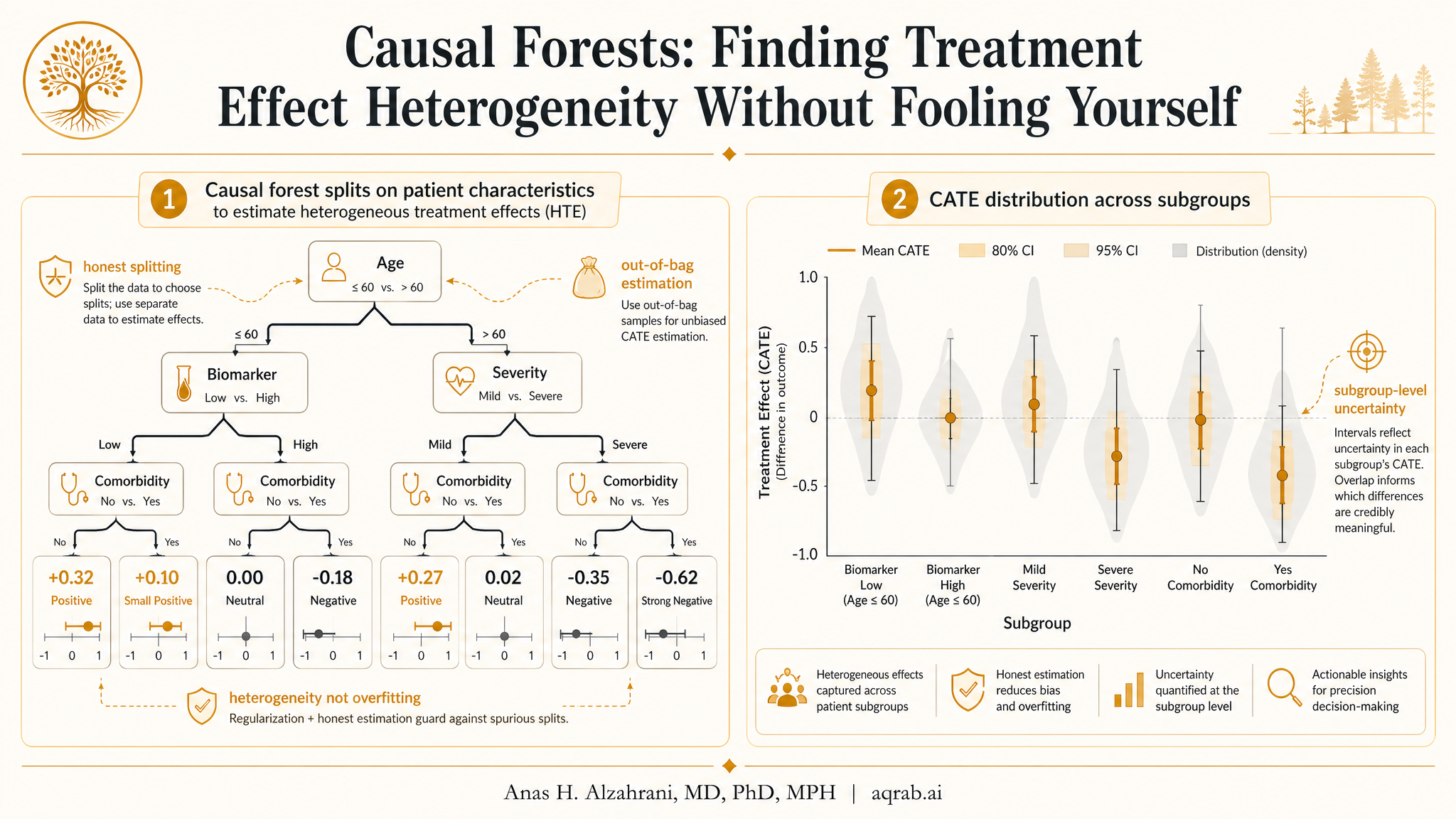
Average treatment effects are useful, but they flatten reality. In clinical research, patients do not respond identically. A drug can help one subgroup, do nothing for another, and quietly harm a third. Causal forests were built for that problem: estimating heterogeneous treatment effectswithout turning subgroup analysis into statistical fan fiction. This guide covers what causal forests do, when they earn their keep, how they fail, and what a serious paper should report.
In this guide
- 1. Why average effects fail
- 2. What causal forests actually estimate
- 3. Honest splitting: the trick that makes them causal
- 4. When causal forests are worth using
- 5. Clinical example: who benefits from GLP-1 therapy?
- 6. How to interpret CATEs without lying to yourself
- 7. Six failure modes that break most analyses
- 8. What reviewers should expect
- 9. Software and implementation
- 10. Getting automated critique with Aqrab
1. Why average effects fail
Most causal inference papers report a single number: the average treatment effect. That is fine if your treatment effect is roughly constant. It is weak if treatment response varies meaningfully across age, baseline severity, genetics, comorbidity burden, adherence, or timing. The average can be positive even when the intervention is useless for half the population.
This is the clinical problem behind the hype around precision medicine. The real question is not just does treatment work? It is for whom, under what baseline profile, and by how much?Traditional subgroup analysis handles this badly. You pick a few cut points, run interaction terms, and hope the p-values behave. They usually don't.
Why ordinary subgroup analysis is a mess
- Arbitrary cut points throw away information
- One-variable-at-a-time thinking misses interactions
- Post hoc subgroup fishing explodes the false positive rate
- Significant interaction p-values are unstable in realistic samples
- Clinical interpretation becomes a story-telling contest
Causal forests are one answer to that problem. Not magic. Not a free precision-medicine machine. But a disciplined way to estimate conditional average treatment effects while separating signal from overfit nonsense better than most ad hoc subgroup workflows.
2. What causal forests actually estimate
A causal forest estimates the treatment effect conditional on covariates:
τ(x) = E[Y(1) − Y(0) | X = x]
That τ(x) is the CATE — the conditional average treatment effect for patients with baseline profile x.
The forest builds many trees, each splitting the data into subgroups where treatment effects appear more homogeneous within leaves and more different across leaves. But unlike ordinary prediction trees, the objective is not just predicting the outcome. The objective is learning how the difference between treated and untreated potential outcomes varies across covariate space.
What causal forests are good at
- • Discovering non-linear treatment effect heterogeneity
- • Capturing interactions you did not pre-specify
- • Estimating patient-level or subgroup-level CATEs
- • Ranking patients by expected benefit
- • Supporting treatment prioritization or policy learning
What they do not solve
- • Unmeasured confounding
- • Bad causal identification strategy
- • Positivity failures / no overlap
- • Tiny sample sizes with fantasy-level precision
- • Clinical interpretation without subject-matter knowledge
This is the key thing people miss: causal forests are an estimation method, not an identification strategy. They sit downstream of your DAG, your confounder set, your overlap assumptions, and your study design. If the design is trash, the forest will estimate heterogeneity in trash.
3. Honest splitting: the trick that makes them causal
Random forests are great at overfitting if you let them. The core innovation in causal forests, especially the generalized random forest framework from Athey, Tibshirani, and Wager, is honesty. The data used to choose splits are separated from the data used to estimate treatment effects within leaves.
- 1Take a subsample of the data for one tree.
- 2Use one part of that subsample to decide where the tree should split.
- 3Use the held-out part to estimate treatment effects inside the leaves.
- 4Repeat this across many trees and average the resulting treatment effect estimates.
That sounds like a technical detail. It isn't. Without honesty, the tree uses random noise twice — once to decide where the “interesting” subgroup is, and again to estimate the subgroup effect. That gives you exaggerated heterogeneity and fake confidence. Honesty reduces that bias.
Clinical translation
Honest splitting is why causal forests are not just “subgroup analysis with trees.” They deliberately make it harder to fool yourself with patterns that only exist because the algorithm stared too long at the same sample.
4. When causal forests are worth using
Use causal forests when heterogeneity is central to the question, your sample is reasonably large, and you have credible covariate information measured before treatment. If all you want is the overall ATE, simpler estimators are easier to explain and often more efficient.
Strong use cases
- • Precision medicine or treatment prioritization questions
- • Large RCTs with suspected effect modification
- • Large observational datasets with rich baseline covariates
- • Non-linear interactions you cannot reasonably pre-specify
- • Policy questions where ranking likely responders matters
Use something else when
- • The sample is small or the treated group is sparse
- • Overlap is poor in important covariate regions
- • You have a pre-specified biologic interaction that standard models can test directly
- • Time-varying confounding is the real problem — use MSMs or g-methods
- • Reviewers need a directly interpretable parametric model and heterogeneity is secondary
My blunt take: if your dataset has 300 patients and you want patient-level treatment recommendations, causal forests are probably bullshit. They need data density. Not infinite data, but enough information that local comparisons are meaningful.
5. Clinical example: who benefits from GLP-1 therapy?
Suppose you want to estimate which patients with obesity and type 2 diabetes derive the largest reduction in major adverse cardiovascular events from initiating a GLP-1 receptor agonist versus an alternative second-line agent.
Treatment
- GLP-1 receptor agonist initiation within 30 days of treatment decision
Outcome
- Two-year risk of MACE
Baseline covariates
- Age, sex, BMI, HbA1c, eGFR, LDL
- Established ASCVD, heart failure, CKD, prior stroke
- Medication history, adherence proxies, utilization history
- Socioeconomic proxies, insurance type, site of care
Why heterogeneity matters
- Benefit likely differs by baseline CV risk
- Toxicity and discontinuation vary with GI tolerance and adherence
- Absolute risk reduction may be concentrated in high-risk subgroups
A causal forest might show that younger low-risk patients have near-zero absolute benefit, while older patients with established ASCVD and high baseline risk have substantially larger predicted benefit. That is clinically useful — but only if you report uncertainty honestly and do not pretend the model found individualized truth for every patient.
What the estimand should look like
Decide whether you care about relative effect heterogeneity or absolute risk reduction heterogeneity. Clinicians often care more about the latter. A model that only ranks relative treatment effect may miss where the real absolute benefit lives.
6. How to interpret CATEs without lying to yourself
The most honest way to use causal forests is not to claim “this exact patient has a treatment effect of 3.7%.” That level of certainty is fake. A better workflow is:
- • Estimate CATEs across patients
- • Group patients into quantiles or clinically interpretable risk-benefit strata
- • Compare observed or estimated treatment effects across these strata
- • Check whether the ranking generalizes out of sample
- • Translate findings into decision support cautiously, not as oracle output
In practice, causal forests are strongest as a ranking tool and a heterogeneity discovery tool. They are weaker as a basis for exact individualized treatment rules unless you have very strong validation. Distinguish exploratory heterogeneity from deployable treatment assignment.
Do not say this
“Our model identified the optimal treatment for each patient.” No it didn't. It estimated treatment heterogeneity under assumptions, in one sample, with finite precision. Keep your swagger under control.
7. Six failure modes that break most analyses
1. Using causal forests without a causal design
If confounders are unmeasured, treatment timing is misaligned, or immortal time bias is present, the forest will estimate heterogeneity in a biased estimand. Garbage in, heterogeneity-shaped garbage out.
2. Ignoring overlap
When some regions of covariate space are almost always treated or untreated, local treatment effect comparisons become unstable or unidentified. Always inspect propensity score overlap and the distribution of forest weights.
3. Small samples with high-dimensional covariates
The model will happily carve the data into leaves that feel precise but are mostly noise. Honest splitting helps, but it cannot create information that is not there.
4. Confusing prognostic effects with treatment effect heterogeneity
Patients at high baseline risk often have worse outcomes regardless of treatment. A model that predicts outcome well is not automatically a model that identifies treatment effect modification well.
5. Declaring discovered subgroups as biologic truth
The forest finds partitions that optimize treatment effect separation in the sample. Those subgroups are statistical summaries, not necessarily biologic entities. Replication matters.
6. No external or out-of-sample validation
A heterogeneity ranking that looks brilliant in the training sample can collapse in a new cohort. If you want decision support, validate transportability before you open your mouth.
8. What reviewers should expect
If a paper uses causal forests and only reports a pretty heterogeneity plot, that is not enough. The reporting standard should be much higher.
Target estimand: ATE, CATE, RATE, policy value, or subgroup effect — name it explicitly
Identification strategy: DAG-based confounder set, treatment timing, and why exchangeability is plausible
Sample size and treatment prevalence, including whether data density supports heterogeneity estimation
Forest specification: number of trees, honesty, sample fractions, minimum leaf size, tuning strategy
Covariates available to the forest, all measured before treatment initiation
Overlap diagnostics: propensity score distributions, trimming rules, and sparse regions
Validation: out-of-bag diagnostics, held-out ranking performance, or external validation cohort
Interpretation scale: risk difference, risk ratio, hazard scale, or transformed outcome framework
Calibration of heterogeneity: do higher predicted-benefit strata actually show larger observed effects?
Sensitivity analysis for unmeasured confounding and model dependence
One more thing: show the boring stuff. Reviewers should see overlap plots, event counts, and validation performance — not just an eye-catching tree diagram and a claim that machine learning found “hidden subgroups.”
9. Software and implementation
The most widely used implementation is the grf package in R. Python users often reach for EconML, which provides causal forest-style estimators and related learners. The right package matters less than whether you understand the estimand, overlap, and validation plan.
Quick sketch in R with grf
library(grf)
forest <- causal_forest(
X = covariates,
Y = outcome,
W = treatment,
num.trees = 2000,
honesty = TRUE,
tune.parameters = "all"
)
cate_hat <- predict(forest)$predictions
ate_hat <- average_treatment_effect(forest)
# Rank patients into quartiles of predicted benefit
quartile <- cut(cate_hat, quantile(cate_hat, probs = seq(0, 1, 0.25)), include.lowest = TRUE)
That code is the easy part. The hard part is whether your covariates are pre-treatment, whether your treatment definition avoids immortal time bias, whether overlap holds, and whether your heterogeneity ranking survives validation.
10. Getting automated critique with Aqrab
Aqrab is built for exactly this kind of methodological weak spot. If your study claims treatment effect heterogeneity, Aqrab checks whether the estimand is clear, whether the design actually supports causal interpretation, whether overlap is plausible, and whether your reporting is doing science or marketing.
Try Aqrab free
Paste your protocol, methods, or draft and get a structured critique in under a minute.
Keep reading
Don't stop at one method.
Good methods judgment comes from contrast. Read the neighboring guides, see where the assumptions diverge, and avoid treating every observational problem like it needs the same hammer.
Targeted Maximum Likelihood Estimation: Doubly Robust, Not Doubly Forgiving
A practical guide to targeted maximum likelihood estimation for clinical researchers. Covers nuisance models, clever covariates, machine learning, overlap diagnostics, and why TMLE is robust in theory but never permission to stop thinking.
Double Machine Learning: A Practical Guide for Clinical Researchers
How DML uses machine learning to estimate causal effects while controlling for high-dimensional confounders. Covers cross-fitting, Neyman orthogonality, clinical applications, and implementation in EconML.
Treatment-Induced Mediator-Outcome Confounding: When Mediation Analysis Starts Chasing the Consequences of Treatment
A practical guide to treatment-induced mediator-outcome confounding for clinical researchers. Covers why natural direct and indirect effects fail when treatment changes later severity, toxicity, adherence, or surveillance that affect both the mediator and outcome.
Further Reading
- Athey S, Tibshirani J, Wager S. Generalized random forests. Annals of Statistics. 2019;47(2):1148-1178.
- Wager S, Athey S. Estimation and inference of heterogeneous treatment effects using random forests. Journal of the American Statistical Association. 2018;113(523):1228-1242.
- Künzel SR, Sekhon JS, Bickel PJ, Yu B. Metalearners for estimating heterogeneous treatment effects using machine learning. Proceedings of the National Academy of Sciences. 2019;116(10):4156-4165.
- Hernán MA, Robins JM. Causal Inference: What If. Chapman & Hall/CRC. 2020.
- Athey S, Wager S. Policy learning with observational data. Econometrica. 2021;89(1):133-161.