Bias Amplification: When Adjustment Makes Unmeasured Confounding Worse
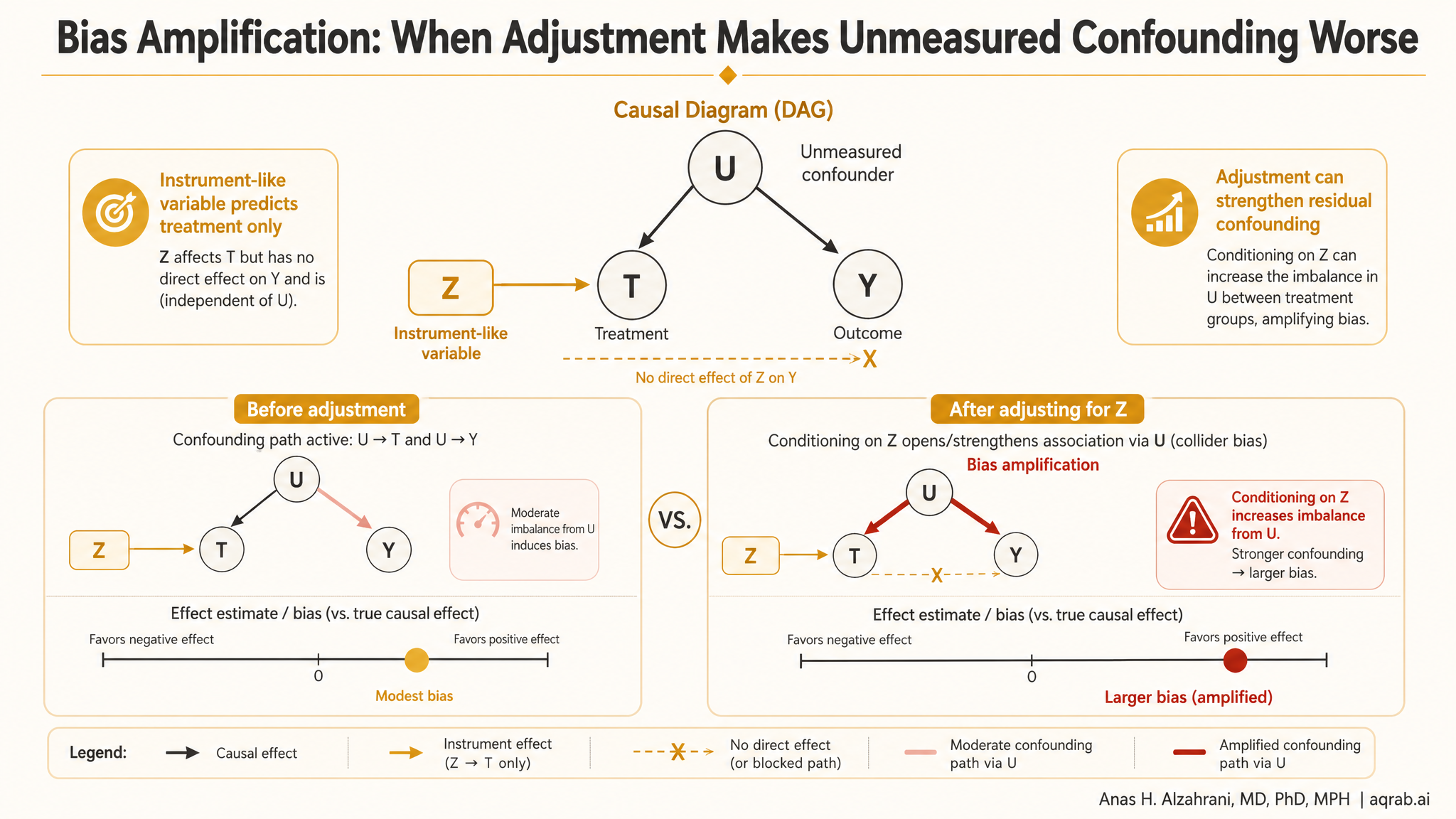
Most researchers have been taught the same instinct: if you are worried about confounding, adjust for more variables. That instinct sounds responsible. It also causes real damage. Sometimes adding a variable does not reduce bias. It amplifies it.
My take is simple: the biggest covariate set is not the safest one. If you condition on a strong predictor of treatment that is not a true confounder, especially when unmeasured confounding is still floating around in the background, you can make the remaining bias worse. Cleaner-looking model. Dirtier causal estimate.
What Bias Amplification Actually Means
Bias amplification happens when adjustment increases the distortion created by unmeasured confounding instead of shrinking it. The classic setup is an observational study with an unmeasured factor that affects both treatment and outcome. Then the analyst adjusts for another variable that strongly predicts treatment but does not help block the real backdoor path.
Core problem:
A variable can explain treatment assignment without helping causal identification. Conditioning on it can make the hidden confounding matter more, not less.
This is why “predictive” and “causally useful” are not the same thing. A great treatment predictor can still be a terrible adjustment variable.
The Fast Intuition
Imagine treatment choice depends on two things: one measured variable and one unmeasured variable. You adjust for the measured one. Now within levels of that measured variable, treatment variation is driven even more heavily by the unmeasured one. You have effectively concentrated the remaining selection problem into a smaller slice of variation.
That is the intuition behind amplification. The model says, “look, I controlled for a strong exposure predictor.” Reality says, “great, now the untreated-versus-treated difference that remains is even more contaminated by the factor you failed to observe.”
Where This Shows Up in Real Research
Near-instruments
Variables that strongly predict treatment but have little or no direct relationship to the outcome except through treatment.
Administrative policy quirks
Formularies, prescriber preference, clinic routing, or insurance rules can drive treatment choice without solving the confounding that matters clinically.
Noisy severity proxies
Weak measures of disease severity can partially explain treatment assignment while leaving most true severity unmeasured and still biasing the comparison.
The Clinical Example
Suppose you are comparing two antihypertensive drugs using EHR data. True cardiovascular risk and frailty affect both treatment choice and outcome, but they are measured badly. Meanwhile, one physician-group prescribing preference is captured perfectly in the data.
- Frailer patients are more likely to receive Drug A.
- Frailty also increases the risk of hospitalization.
- Prescribing preference strongly predicts Drug A versus Drug B.
- Prescribing preference is not the true source of outcome risk.
If you adjust aggressively for prescribing preference while frailty remains poorly measured, the remaining treated-versus-untreated contrast can become more dominated by frailty. That means more residual confounding, not less.
Why Instruments and Near-Instruments Are Dangerous in Adjustment Sets
A true instrumental variable affects treatment, does not directly affect the outcome, and is not confounded with the outcome. That sounds valuable — and it is, when used as an instrument with a proper IV design. It is not automatically valuable as a routine adjustment covariate in regression or propensity scores.
| Variable type | Useful for prediction? | Useful for confounding control? |
|---|---|---|
| True confounder | Often yes | Yes — this is what you want to block. |
| Instrument / near-instrument | Usually yes | Not necessarily. Can amplify hidden bias if treated like a routine covariate. |
| Mediator / post-treatment variable | Sometimes | No for total effects. Creates a different problem entirely. |
If the goal is treatment prediction, instruments can look excellent. If the goal is causal adjustment, that same excellence can be exactly the trap.
Propensity Scores Are Not Immune
This problem gets worse because people treat propensity score models like exposure-prediction competitions. They brag when the c-statistic is high. I worry when the c-statistic is too high for the wrong reason.
A propensity model packed with near-instruments can separate treated from untreated patients beautifully while making overlap worse, increasing weight instability, and amplifying the influence of unmeasured confounding that still explains residual treatment choice. Better prediction of treatment does not guarantee better causal estimation.
The Common Mistake in Variable Selection
Analysts often choose covariates because they predict treatment, are statistically significant, or are easily available. None of those is a causal criterion. The real question is whether the variable helps block a backdoor path between treatment and outcome.
If you cannot explain why a variable belongs in the adjustment set using a causal diagram or explicit subject-matter logic, you are probably doing convenience epidemiology. That is where amplification thrives.
How to Spot Amplification Risk Before It Bites You
1. Treatment prediction is strong, outcome relevance is weak
That is a red flag for a near-instrument rather than a confounder.
2. Unmeasured severity is still plausible
If the real clinical driver is only partly measured, aggressive adjustment for cleaner administrative predictors may worsen the remaining bias.
3. Overlap gets worse after adding the variable
Extreme propensity scores and unstable weights often signal that you just sharpened treatment selection without improving identification.
4. The causal rationale sounds hand-wavy
“It seemed important” is not a design principle.
What Good Studies Do Instead
Start with a DAG
Decide whether a variable is a confounder, instrument, collider, mediator, or proxy before it enters the model.
Prioritize outcome-relevant confounders
Variables related to the outcome often matter more for confounding control than variables that merely predict treatment.
Report overlap honestly
If a covariate wrecks common support, do not pretend the model improved just because discrimination increased.
Run sensitivity analyses on variable sets
Show how estimates move when near-instruments or weak proxies are included versus excluded.
Reviewer Red Flags
- Propensity score models justified by prediction metrics instead of causal reasoning.
- Covariates included because they are “strong predictors of treatment” with no discussion of outcome relevance.
- Major loss of overlap or extreme weights after adding administrative or preference-driven variables.
- No DAG, no variable classification, and no explanation of why a treatment predictor should reduce confounding.
- Claims of robustness because “we adjusted for everything available.”
That last line should make you nervous, not reassured. Everything available is not the same thing as everything causally appropriate.
The Practical Bottom Line
Bias amplification is the reminder that adjustment is not automatically a virtue. The wrong variable can make hidden bias bigger, sharpen positivity problems, and create false confidence in a bad design.
The fix is not more modeling theater. It is better causal thinking: draw the DAG, distinguish confounders from instruments, respect overlap, and stop treating treatment prediction as the same job as causal identification. If a variable does not help block bias, it does not deserve a seat in the adjustment set just because the software can include it.
Keep reading
Don't stop at one method.
Good methods judgment comes from contrast. Read the neighboring guides, see where the assumptions diverge, and avoid treating every observational problem like it needs the same hammer.
Negative Controls: The Bias Check Most Observational Studies Skip
A practical guide to negative control outcomes and exposures for clinical researchers. Covers residual confounding, selection bias, surveillance bias, falsification endpoints, and how to interpret a failed negative control without lying to yourself.
Measurement Error: When Bad Variables Break Good Causal Methods
A practical guide to measurement error for clinical researchers. Covers noisy exposures, weak confounder proxies, surveillance-driven outcomes, validation strategies, and why sophisticated causal methods cannot rescue bad variables.
Misclassification Bias: When Your Variables Lie Before the Model Starts
A practical guide to misclassification bias for clinical researchers. Covers wrong exposure and outcome labels, weakly measured confounders, surveillance-driven event detection, and why bad variables can distort causal estimates before modeling even begins.