Collider Bias: How Adjustment Can Manufacture Associations
Researchers love adjustment. Add more variables, make the model look sophisticated, cite a famous paper, and call it rigor. The problem is that some variables should never be conditioned on. A collideris one of them. If you adjust for a variable caused by both the exposure and the outcome, you can create an association that did not exist before. Not reveal it. Create it.
That is why collider bias is so nasty. It feels like careful analysis while it quietly sabotages causal inference. It also explains a huge amount of selection bias in hospital cohorts, registry studies, volunteer samples, complete-case analyses, and basically any dataset built by conditioning on who showed up, who got tested, or who survived long enough to be counted.
The Core Idea
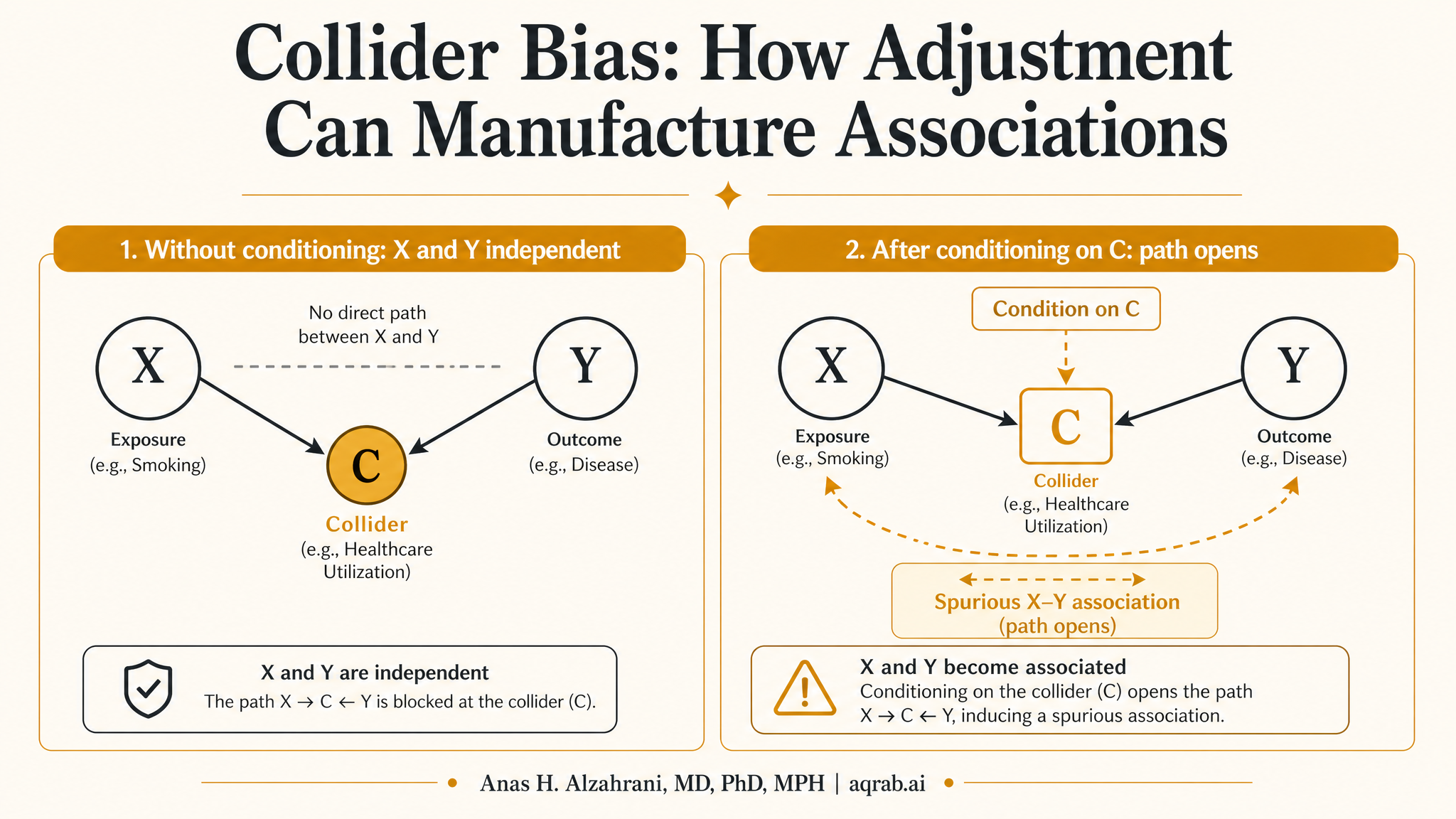
A collider is a variable with two arrows pointing into it. In DAG language, it looks like this:
A → C ← Y
Exposure A and outcome Y both cause C. If you condition on C, or on a descendant of C, you open a non-causal path between A and Y.
Unconditioned, that path is blocked. Condition on the collider, and the path opens. Suddenly exposure and outcome look statistically related even if they are otherwise independent. That is the opposite of what most people think adjustment does.
Why This Happens
Intuitively, once you restrict to a subgroup defined by a common effect, information about one cause tells you something about the other. If a patient is admitted to the ICU, and ICU admission is influenced by both disease severity and a treatment-related complication, then among ICU patients the treatment and severity can become associated even if they were not associated before selection.
Classic intuition:
If a journal only accepts applicants who are either brilliant or famous, then among accepted authors, brilliance and fame will look negatively correlated. Why? Because conditioning on acceptance induced the relationship.
Same math, less ego, applies in clinical data all the time.
Collider Bias vs Confounding
People mix these up constantly, which is how they end up adjusting for the very thing breaking the study.
Confounder
Common cause of exposure and outcome.
Usually should be controlled.
Pattern: U → A and U → Y.
Collider
Common effect of exposure and outcome.
Usually should not be controlled.
Pattern: A → C and Y → C.
The tragic part is that both confounders and colliders often look like “important clinical covariates.” Domain knowledge without causal structure is not enough. You need the graph.
Where Collider Bias Shows Up in Real Research
Hospital-based samples
If both exposure and disease severity affect hospitalization, restricting analysis to hospitalized patients can induce fake associations that do not exist in the source population.
Testing and screening cohorts
When both symptoms and healthcare access affect who gets tested, analyses among tested individuals can produce distorted exposure-outcome relationships.
Complete-case analysis
Missingness can behave like a collider when both prognosis and treatment influence who has complete data. Dropping incomplete records is not a neutral act. Sometimes it is bias with cleaner formatting.
Survivor cohorts
Restricting to people who survive until cohort entry can induce selection bias when both prior exposure and frailty affect survival. Congratulations, you just created a healthier exposed group by design.
A Clinical Example
Imagine you want to study whether obesity is associated with mortality among patients admitted to the ICU. You find that obesity appears protective, then someone gets excited about the so-called obesity paradox. Slow down.
ICU admission may itself be influenced by both obesity and severity of illness. By conditioning on ICU admission, you may open a path between obesity and severity. If severe lean patients are more likely to be admitted than less severe lean patients, while obese patients are admitted at a lower severity threshold, then the admitted sample becomes causally distorted. Inside that distorted subgroup, obesity can look protective even if no such protection exists in the broader population.
Takeaway:
The paradox may be in the selection mechanism, not in adipose tissue performing miracles.
Why “Adjustment for Everything” Is Bad Causal Hygiene
Collider bias is one of the main reasons automated variable selection is a terrible substitute for study design. Stepwise regression, significance-based screening, and kitchen-sink propensity models do not know what a collider is. They only know association. Causal inference is about structure, not just fit.
This matters especially in high-dimensional clinical datasets. Variables related to healthcare utilization, disease detection, referral, testing, and treatment decisions can be descendants of multiple upstream causes. They often feel too important to omit, which is exactly why they are dangerous.
Selection Bias Is Often Collider Bias Wearing a Different Hat
Many researchers talk about selection bias as if it were a separate planet. Often it is just collider bias induced by conditioning on inclusion. Participation, retention, diagnosis, hospitalization, and survival can all be colliders or descendants of colliders.
If both exposure and outcome influence whether someone enters your analytic sample, then the sample itself is a selected collider. That is why convenience cohorts are not merely less generalizable. They can be internally biased too.
How to Detect the Risk Before You Analyze
- Draw the DAG before looking at model output.
- Ask what determined cohort entry, testing, follow-up, and measurement.
- Mark every variable that could plausibly be caused by both exposure and prognosis.
- Be suspicious of post-baseline variables, utilization markers, and convenience-sample indicators.
- If a variable lives downstream of multiple processes, do not “adjust first, think later.”
The earlier you do this, the better. Once a result looks exciting, people become very inventive about defending bad conditioning choices.
Can You Fix Collider Bias After the Fact?
Sometimes, but not with wishful thinking. If selection is understood and measured, methods like inverse probability weighting for selection can help. Sensitivity analysis can quantify how robust conclusions are to plausible selection mechanisms. Better design can prevent the problem entirely by redefining time zero, eligibility, or sampling.
What does not work is adjusting for the collider harder, throwing in more downstream covariates, or calling the issue a limitation while keeping the abstract causal. If the analytic sample is structurally biased, model polish will not save it.
What Reviewers Should Expect
- A stated causal question, not just an association dressed up with confidence intervals.
- A DAG or explicit design logic showing why adjusted variables are confounders rather than colliders or mediators.
- A transparent cohort construction story explaining who was included, excluded, tested, hospitalized, or observed.
- Sensitivity analyses when selection into the analytic sample may depend on both exposure and prognosis.
- Interpretive restraint when collider bias cannot be reasonably ruled out.
Common Mistakes
Adjusting for post-treatment variables by reflex
If the variable happens after exposure, it might be a mediator, a collider, or both. Earn the right to include it.
Mistaking availability for validity
Just because a claims database has utilization metrics does not mean those metrics belong in the adjustment set.
Calling a selected cohort “the study population” without asking how selection happened
Inclusion criteria are part of the causal model. They are not administrative wallpaper.
The Bottom Line
Collider bias is the reason “more adjustment” is not automatically better. Sometimes the variable you are controlling for is the exact switch that turns a clean causal question into nonsense. If your study conditions on who got admitted, who got tested, who responded, who survived, or who had complete data, you should assume collider risk until proven otherwise.
Good causal work is not about squeezing every variable into a model. It is about knowing which doors to keep closed.
Keep reading
Don't stop at one method.
Good methods judgment comes from contrast. Read the neighboring guides, see where the assumptions diverge, and avoid treating every observational problem like it needs the same hammer.
Selection Bias: When Your Study Sample Is the Problem
A practical guide to selection bias for clinical researchers. Covers referral filtering, survivor bias, complete-case analysis, informative loss to follow-up, collider-driven selection, and why a clean model cannot rescue a distorted sample.
Treatment-Induced Mediator-Outcome Confounding: When Mediation Analysis Starts Chasing the Consequences of Treatment
A practical guide to treatment-induced mediator-outcome confounding for clinical researchers. Covers why natural direct and indirect effects fail when treatment changes later severity, toxicity, adherence, or surveillance that affect both the mediator and outcome.
Stochastic Interventions: When “Treat Everyone” Is Not the Policy Question
A practical guide to stochastic interventions for clinical researchers. Covers when deterministic treatment rules become unrealistic, how probability-shift interventions preserve positivity, and what reviewers should demand before trusting policy-effect claims.