Confounding by Indication: When Sicker Patients Make Treatments Look Dangerous
Confounding by indication is one of the oldest traps in clinical research, and people still fall into it like it is a hidden hole. The problem is brutally simple: treatments are not assigned at random in routine care. Clinicians give them for reasons, and those reasons usually have a lot to do with prognosis.
My take is blunt. If the sickest patients are more likely to get the treatment, then a crude outcome comparison is mostly measuring clinical judgment, not treatment effect. When a paper ignores that, it is not doing comparative effectiveness research. It is comparing people who were treated for different reasons and pretending the therapy caused the difference.
What Confounding by Indication Actually Means
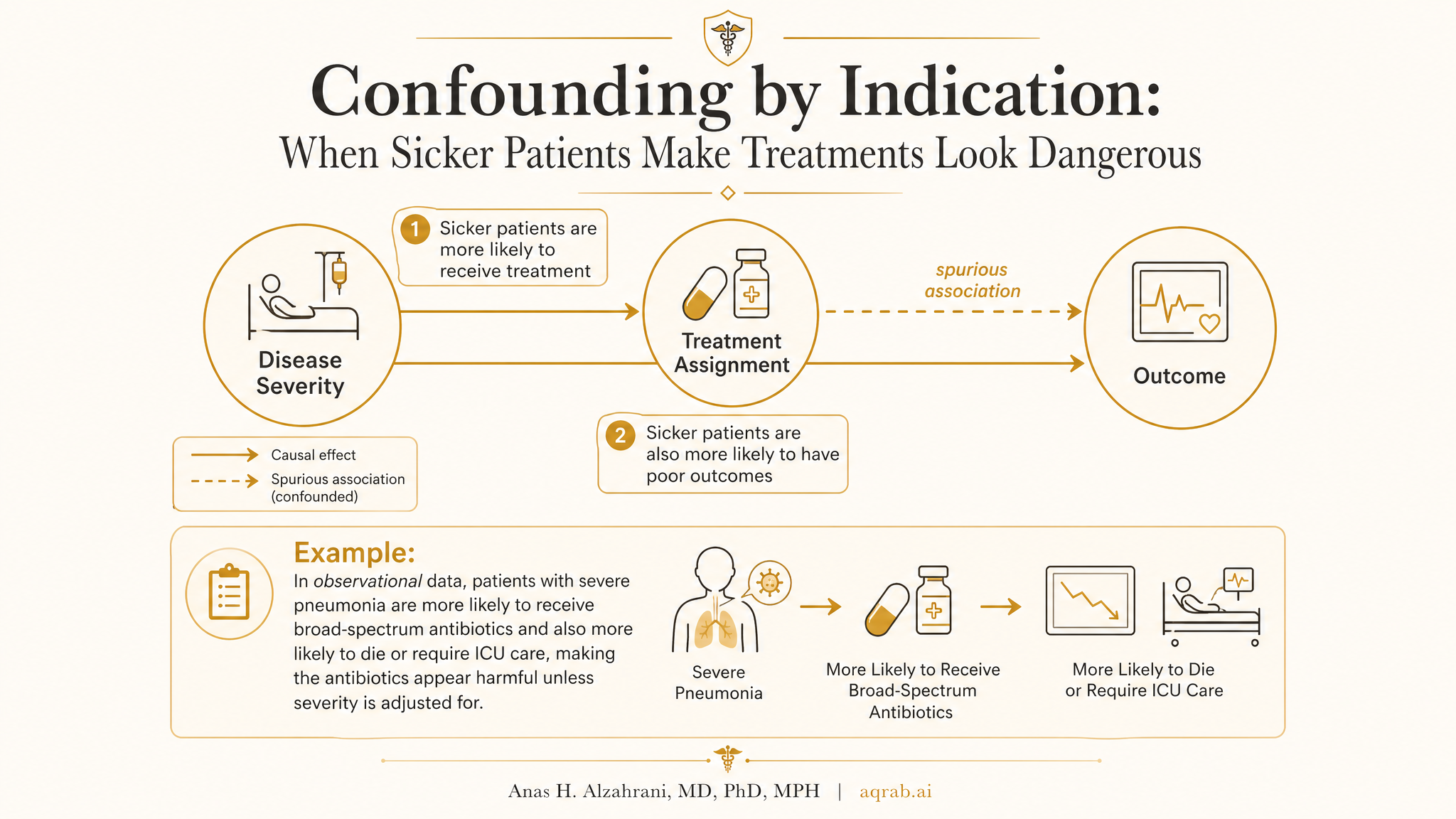
Confounding by indication happens when the reason a patient receives a treatment is itself related to the outcome. In real practice, doctors prescribe stronger, riskier, or newer treatments to patients who look worse, more complicated, or more urgent. That means the treated group often starts out with a different prognosis before the drug, procedure, or device even gets a chance to work.
Core problem:
Treatment choice carries information about baseline risk, severity, contraindications, and clinician judgment.
If you do not account for that decision process, bad outcomes in the treated group can reflect why they were treated rather than what the treatment did.
The Classic Clinical Example
Imagine an observational study comparing mortality in patients with severe infection who did versus did not receive broad-spectrum antibiotics. The treated group looks worse. Does that mean the antibiotics are harmful? Not so fast.
- Patients with higher fever, shock, rising lactate, or organ dysfunction are more likely to get aggressive treatment.
- Those same features predict death even if treatment is beneficial.
- The treatment group may therefore look doomed at baseline before the first dose is given.
A naive analysis will happily label that baseline severity difference as a treatment effect.
Why the Bias Is So Dangerous
Confounding by indication can make effective treatments look harmful, neutral treatments look helpful, and weak therapies look like miracle rescues if they are preferentially given to carefully selected patients. It is especially vicious in pharmacoepidemiology, ICU studies, oncology, and surgical comparisons where treatment choice is tightly linked to disease severity and fitness for intervention.
What gets tangled together
Treatment effect, baseline severity, clinician intuition, access to care, contraindications, frailty, and timing of deterioration.
What gets missed
The fact that “why this patient got treated” is often more prognostic than any single covariate sitting in the database.
How to Spot It Fast
If I am screening a paper for confounding by indication, I ask four questions immediately:
Why would a clinician choose this treatment?
If the answer is “because the patient looked worse” or “because the patient looked healthier and eligible,” the design is already under stress.
Are severity drivers measured well?
Administrative data usually miss nuance: symptom burden, imaging findings, clinician gestalt, patient preference, and urgency at the bedside.
Could contraindication patterns distort the comparison?
Sometimes untreated patients are not lower risk. They are too frail, too unstable, or too complex to receive the intervention safely.
Does the paper act as if adjustment solved everything?
That is usually the tell. The authors balanced what they measured and quietly ignored everything that drove treatment choice but never made it into the dataset.
Where It Commonly Shows Up
- Comparing aggressive rescue therapies against standard care in ICU cohorts.
- Comparing surgery versus no surgery when frailty and operability are poorly captured.
- Comparing newer cancer regimens with older regimens when line of therapy and tumor burden differ.
- Comparing anticoagulation use when bleeding risk and physician caution shape who gets treated.
- Comparing vaccination, screening, or preventive medication uptake when health-seeking behavior is uneven.
Different clinical areas, same core issue: treatment assignment is informative.
Why Regression Usually Does Not Magically Fix It
Standard multivariable adjustment can help, but it does not become causal just because the model has many covariates. If the key drivers of treatment choice are missing, poorly measured, or mis-timed, the regression coefficient is still contaminated.
| Approach | What it helps with | What it cannot rescue |
|---|---|---|
| Ordinary regression | Measured baseline confounders | Unmeasured severity, bad time alignment, treatment indication hidden in clinician judgment |
| Propensity scores | Balancing observed treatment predictors | Missing predictors, contraindication bias, positivity failures, future variables |
| Instrumental variables | Potentially addresses unmeasured confounding | Weak or invalid instruments, local effects misread as universal effects |
| Target trial emulation | Design clarity, time-zero alignment, explicit strategy comparison | Still depends on measuring the right confounders and honoring eligibility logic |
Confounding by Indication vs Healthy User Bias
These two get mixed up constantly, but they are not the same. Confounding by indication usually means the treated group is sicker because treatment is triggered by risk or severity. Healthy user bias is almost the reverse: patients who seek preventive care or adhere to chronic therapy often look healthier, more organized, and more advantaged in ways that also improve outcomes.
A Practical Example in Surgical Outcomes
Suppose you compare survival after revascularization versus medical therapy in patients with complex coronary disease. The surgical group may be younger, anatomically suitable, and robust enough to tolerate a major procedure. Or the opposite: maybe surgery is reserved for the sickest anatomy and most severe ischemic burden.
Either way, treatment selection is not random. It reflects clinical reasoning about anatomy, comorbidity, frailty, operative risk, and expected benefit. If your data do not capture those factors well, your estimate is partly a shadow of selection rather than a clean treatment effect.
What Better Design Looks Like
There is no magic wand, but there are serious ways to reduce the damage.
Define the clinical decision point clearly
Start with the moment a patient could realistically receive either strategy. If the comparison is not fair at time zero, the rest is theater.
Measure the indication, not just demographics
Severity scores, symptom burden, prior treatment history, contraindications, labs, imaging, and clinician-facing decision variables matter more than generic baseline tables.
Choose an estimand that matches the question
Average treatment effect, treatment effect in the treated, per-protocol effect, and dynamic strategy effects are not interchangeable. Sloppy estimands create sloppy comparisons.
Use negative controls and sensitivity analysis
If residual confounding is plausible, act like it. Stress-test the claim instead of pretending your adjustment set achieved purity.
Reviewer Red Flags
- The treated group is obviously sicker or healthier at baseline and the discussion shrugs.
- Authors say “we adjusted for all important confounders” without showing how treatment decisions are made clinically.
- Severity is represented by a few coarse claims codes while bedside decision variables are missing.
- Massive treatment effects appear in settings where confounding by indication is almost guaranteed.
- Propensity score balance is presented as if it proves causal identification.
When authors sound too relaxed about selection into treatment, I assume the estimate is carrying more bias than they admit.
What Good Reporting Looks Like
A serious paper should make these points explicit:
- the exact clinical decision moment being emulated,
- the observed factors that drive treatment selection,
- which likely treatment drivers are missing or imperfectly measured,
- how overlap and positivity were assessed,
- which estimand is being targeted,
- what sensitivity analyses probe residual confounding,
- why the authors believe the comparison is clinically credible.
If a paper never explains why some patients got the treatment and others did not, it probably does not understand its own confounding structure.
The Bottom Line
Confounding by indication is what happens when the clinical reason for treatment hijacks the analysis. The sickest patients often get the strongest treatments, and the healthiest patients often get the interventions they are fit enough to receive. Either way, treatment choice is telling you something about prognosis.
That means observational comparisons live or die on design quality, variable quality, and honesty about what the data cannot capture. Fancy modeling helps only after the causal question is framed correctly.
My blunt version: if your study treats clinician judgment like randomization, the model is not estimating treatment effect. It is estimating the consequences of pretending medicine is a coin flip.
Keep reading
Don't stop at one method.
Good methods judgment comes from contrast. Read the neighboring guides, see where the assumptions diverge, and avoid treating every observational problem like it needs the same hammer.
Bias Amplification: When Adjustment Makes Unmeasured Confounding Worse
A practical guide to bias amplification for clinical researchers. Covers near-instruments, noisy severity proxies, treatment-prediction traps, and why the wrong adjustment variable can magnify residual confounding instead of reducing it.
Selection Bias: When Your Study Sample Is the Problem
A practical guide to selection bias for clinical researchers. Covers referral filtering, survivor bias, complete-case analysis, informative loss to follow-up, collider-driven selection, and why a clean model cannot rescue a distorted sample.
Proximal Causal Inference: What to Do When Unmeasured Confounding Is Still on the Table
A practical guide to proximal causal inference for clinical researchers. Covers proxy variables, treatment-inducing versus outcome-inducing proxies, bridge functions, completeness, and why this method is powerful but brutally assumption-heavy.